The complete guide: from product idea to fully validated AI feature

Written by Madalina Turlea
01 Dec 2025
Section 1: Why This Guide Exists
This guide distills what we've learned from building AI features systematically and working with product teams across mental health, hrtech, fintech, procurement, logistics, and beyond. It provides an overview of the methodology of getting from an idea to a validated AI feature idea on your data, without requiring any engineering efforts.
Who is this guide for
This guide is designed for product builders who are:
- - Currently working on AI-powered features and want to improve their validation and testing process
- - Planning to add AI features to their roadmap and need to understand how to evaluate feasibility and quality
- - Thinking about AI but don't know where to start—curious but uncertain about next steps
- - Exploring AI product ideas for side projects and want to validate concepts quickly without engineering resources
- - Any role on a product team (PM, Designer, UX Researcher, Engineer) who wants to understand how to contribute to AI feature development
The core problem we’ve been seeing
Most teams are defaulting AI feature exploration to engineering only. How?
- - One of the first decision made is choosing a model based on what's trending on LinkedIn (usually GPT-5 because "it's the best")
- - Prompts are owned by engineering, they live in the codebase and there is little collaboration and validation of different prompting strategies
- - The feature is shipped it to production as beta with very limited testing
- - Teams test the AI feature mostly in production, directly with real users and usage
This is like deploying traditional software without any testing whatsoever. Except AI is non-deterministic – the same input can produce different outputs every time.
Section 2: The Mindset Shift
Here's why AI product development is different: If you test a login feature 100 times successfully, you can be confident it works for user 101. If you test an AI feature 100 times successfully, you have no guarantee it works for case 101. This isn't a bug—it's the nature of AI. Traditional software is deterministic (same input = same output). AI is probabilistic (same input can produce different outputs). This fundamental difference requires a complete shift in how you approach testing, validation, and deployment.
Traditional Software vs. AI Development
| Traditional Software | AI Development |
|---|---|
| Deterministic – works the same way everywhere | Non-deterministic – responses are probabilities |
| Same input = Same output | Same input ≠ Same output |
| Predictable results | Results vary based on context |
| Test once on 100 cases → works on case 101 | Test on 100 cases → can't guarantee case 101 |
How casual usage of ChatGPT/Claude differs from building AI-powered products
Most people's experience with AI is through ChatGPT, Claude, or similar chat interfaces. This creates a critical misconception when building AI products. When you use ChatGPT, you're using a fully-built application with its own system prompts, guardrails, and instructions already configured by OpenAI/Anthropic. You just type your question and get an answer. When you build AI into your product, you're working directly with the API—the raw model without any of that pre-configuration. You need to provide the system instructions, handle edge cases, define output formats, and embed your domain expertise yourself. This is why "it worked in ChatGPT" doesn't mean it will work in your product. You're starting from a completely different foundation.
| Personal AI Use (ChatGPT/Claude) | AI integrated in your Product | |
|---|---|---|
| Problem Scope | Solving one specific problem: Example: "What should I eat for lunch?" | Same instructions must solve the problem across infinite variations Example: "You are tasked to help the user with a quick lunch idea based on its preference" |
| Input Control | You control the input | You don't control user input Example: User can input preference like: – I like a sweet lunch – I like fish – healthy |
| Impact | Results matter only to you | Results affect all your users |
💡 Critical Insight: Context matters enormously in AI. The same question asked in ChatGPT vs. Claude produces different answers – not only because of training data differences, but because each has different system context and instructions.
Section 3: Core Concepts
When integrating AI into your product, you need to understand and experiment with 4 core concepts:
1. System Prompt (Your intelligence layer)
The instructions that give AI context about how to solve for the user need or problem. This is where you embed your domain and product expertise.
To understand the power of a good prompt, we will look at 2 versions of the system prompt.
Assume we are building an AI-powered feature in the Nike app, to help user get a personalized recommendation for running shoes.
Basic Prompt:
You are a helpful assistant.
Based on the user's answers about their running preferences, recommend 2-3 Nike shoes that would be suitable for them.
Structured Prompt:
#Role
You are an expert Nike shoe recommendation system. Your goal is to match users with the most suitable Nike running shoes based on their specific needs, activity patterns, and preferences.
#Your Task
Analyze the user's responses to our shoe finder questionnaire and recommend 2-3 specific Nike shoes ranked by suitability. Each recommendation must reference technical specifications that align with their stated needs.
#User Input Format
You will receive:
Activity type: Primary running activity
Running frequency: How often they run per week
Terrain: Where they primarily run
Comfort priority: What comfort aspect matters most
Experience level: Their running background
#Context
This is the Nike Product Catalog
{{Road Running Shoes}}
#Recommendation Logic
Match user needs to shoes using these criteria:
Activity Type Matching:
Marathon training → Pegasus 41, Vomero 18, Alphafly 3 (if experienced)
Half marathon → Pegasus 41, Zoom Fly 6, Vomero 18
5K/10K → Pegasus 41, Zoom Fly 6, Structure 26 (if stability needed)
Trail running → Terra Kiger 10, Wildhorse 8
Casual/fitness → Revolution 7, Downshifter 13, Motiva
Speed work → Zoom Fly 6, Alphafly 3 (experienced only)
Recovery runs → Vomero 18, Invincible 3
Frequency Considerations:
5+ times/week → Durable options (Pegasus 41, Structure 26, Wildhorse 8)
2-4 times/week → Versatile trainers (Pegasus 41, Vomero 18)
1 time/week or less → Entry-level (Revolution 7, Downshifter 13)
#Output Format
Provide your recommendations in this format:
[Shoe Name] - [Reason]
[Shoe Name] - [Reason]
[Shoe Name] - [Reason]
2. Model Selection
There are hundreds of AI models. Each has different:
- - Strengths and weaknesses
- - Cost structures (can vary 1000x)
- - Response speeds
- - Capabilities
💡 Never choose a model first. Test your use case across multiple models when you are first exploring a new feature.
3. Model Parameters
Each model has multiple parameters you can adjust which will impact output. For example, some models allows for these parameters setup:
- - Temperature: To control creativity vs. determinism in the model’s response
- - Max tokens: Control the response length and cost
- - Top-p: response sampling methods
4. User Input
This is how the end user interacts with the AI-feature in your product. In most cases this is the variable you can't control. Could be:
- - Empty
- - One character
- - A novel
- - Conflicting information
- - Edge cases you never imagined
Section 4: The 6-Step Process
We will take as example a hypothetical Nike AI-feature. In this Built for Mars case study, Peter has uncovered that the running shoe personal recommendation is not in fact personalised. Our hypothesis for this guide is to test whether we can use AI to deliver real AI-personalised recommendation for Nike running shoes.
Step 1: Define Your Experiment
What you need:
- - Clear problem statement
- - Success metrics
- - Expected outputs for test cases
- - Test data that represents real scenarios
Example: Nike AI-Powered Shoe Personalization
Experiment Goal:
Evaluate if AI can deliver genuine shoe personalization by analyzing user preferences and matching them to specific Nike sneaker models with technical justification, replacing the current "fake personalization" that shows same products regardless of user input.
Success Metrics:
Recommendations match user-stated needs (activity type, comfort preferences, terrain) Technical specifications cited align with user requirements Response time is acceptable for real time use in the app Costs can be acceptable at Nike's scale, where millions of personalization requests might be made daily
Step 2: Create Prompt Variations
Start with two extremes to understand the impact:
Variation 1: Basic Prompt (what most tutorials show) - Minimal instructions - No context - Generic format request
```jsx
You are a Nike shoe recommendation assistant.
Based on the user's answers about their running preferences, recommend 2-3 Nike shoes that would be suitable for them.
Include the shoe name and a brief reason why it's a good fit.
You will receive the User preferences for :
Activity type:
Running frequency:
Terrain:
Comfort priority:
Previous experience:
Provide your recommendations in this format:
[Shoe Name] - [Reason]
[Shoe Name] - [Reason]
[Shoe Name] - [Reason]
```
Variation 2: Structured Prompt - Markdown formatting for clarity - Complete domain context - Specific examples - Edge case handling
# Role
You are an expert Nike shoe recommendation system. Your goal is to match users with the most suitable Nike running shoes based on their specific needs, activity patterns, and preferences.
## Your Task
Analyze the user's responses to our shoe finder questionnaire and recommend 2-3 specific Nike shoes ranked by suitability. Each recommendation must reference technical specifications that align with their stated needs.
## User Input Format
You will receive:
- Activity type: Primary running activity
- Running frequency: How often they run per week
- Terrain: Where they primarily run
- Comfort priority: What comfort aspect matters most
- Experience level: Their running background
## Context
This is the Nike Product Catalog
### Road Running Shoes
**Nike Pegasus 41** (Product Code: DV3853)
- Category: Versatile daily trainer
- Cushioning: ReactX foam (13% more energy return than React)
- Weight: 283g (men's size 10)
- Drop: 10mm
- Terrain: Road, treadmill, light trails
- Best for: Neutral runners, daily training, 5K to marathon
- Durability: 400-500 miles
- Support: Neutral
- Customer reviews: 4.6/5 - "Perfect daily trainer," "Great for easy and tempo runs"
- Price: $140
**Nike Vomero 18** (Product Code: FB1309)
- Category: Max cushion trainer
- Cushioning: ZoomX + ReactX dual-foam system (max cushioning)
- Weight: 315g (men's size 10)
- Drop: 10mm
- Terrain: Road, track
- Best for: Long runs, recovery runs, runners seeking maximum comfort
- Durability: 350-450 miles
- Support: Neutral with plush comfort
- Customer reviews: 4.7/5 - "Cloud-like cushioning," "Best for easy long runs"
- Price: $160
**Nike Structure 26** (Product Code: DX2671)
- Category: Stability trainer
- Cushioning: React foam with medial post
- Weight: 297g (men's size 10)
- Drop: 10mm
- Terrain: Road, treadmill
- Best for: Overpronators needing support, daily training
- Durability: 400-500 miles
- Support: Moderate stability (medial post)
- Customer reviews: 4.4/5 - "Great support without feeling rigid," "Prevents knee pain"
- Price: $135
**Nike Alphafly 3** (Product Code: DV4355)
- Category: Racing super shoe
- Cushioning: ZoomX foam with carbon Flyplate and Air Zoom pods
- Weight: 218g (men's size 10)
- Drop: 8mm
- Terrain: Road racing only
- Best for: Experienced runners, race day (marathon/half-marathon)
- Durability: 150-200 miles (racing only)
- Support: Neutral, high energy return
- Customer reviews: 4.8/5 - "PRs guaranteed," "Incredible propulsion"
- Price: $285
**Nike Invincible 3** (Product Code: DR2615)
- Category: Maximum cushion recovery shoe
- Cushioning: ZoomX foam (highest stack height)
- Weight: 331g (men's size 10)
- Drop: 9mm
- Terrain: Road
- Best for: Recovery runs, injury prevention, beginners, maximum comfort
- Durability: 300-400 miles
- Support: Neutral with rocker geometry
- Customer reviews: 4.5/5 - "Like running on pillows," "Saved my knees"
- Price: $180
### Trail Running Shoes
**Nike Terra Kiger 10** (Product Code: FD5190)
- Category: Trail racer
- Cushioning: React foam with responsive ride
- Weight: 261g (men's size 10)
- Drop: 8mm
- Terrain: Technical trails, varied terrain
- Best for: Trail racing, fast trail runs
- Traction: Multi-directional lugs for technical terrain
- Durability: 300-400 miles
- Support: Neutral with trail-specific stability
- Customer reviews: 4.3/5 - "Fast on technical trails," "Great grip"
- Price: $140
**Nike Wildhorse 8** (Product Code: DC9443)
- Category: Trail workhorse
- Cushioning: React foam with rock plate
- Weight: 298g (men's size 10)
- Drop: 8mm
- Terrain: All trail types, rugged terrain
- Best for: Trail runners needing durability and protection
- Traction: Aggressive multi-directional lugs
- Durability: 400-500 miles
- Support: Neutral with underfoot protection
- Customer reviews: 4.5/5 - "Tough and reliable," "Handles anything"
- Price: $135
### Speed Training & Track
**Nike Zoom Fly 6** (Product Code: FQ8105)
- Category: Tempo/speed trainer
- Cushioning: ZoomX foam with carbon plate
- Weight: 241g (men's size 10)
- Drop: 8mm
- Terrain: Road, track
- Best for: Tempo runs, speed work, race training
- Durability: 250-350 miles
- Support: Neutral with propulsion
- Customer reviews: 4.6/5 - "Perfect for tempo days," "Race-day feel in training"
- Price: $170
### Lifestyle/Casual (Running-inspired)
**Nike Pegasus Premium** (Product Code: DN3727)
- Category: Lifestyle runner
- Cushioning: React foam with premium materials
- Weight: 295g (men's size 10)
- Drop: 10mm
- Terrain: Casual wear, light running, gym
- Best for: All-day comfort, gym workouts, casual runners
- Durability: 300-400 miles running / extended casual wear
- Support: Neutral
- Customer reviews: 4.5/5 - "Great for gym and running errands," "Stylish and comfortable"
- Price: $150
**Nike Motiva** (Product Code: FD8781)
- Category: Walking and easy movement
- Cushioning: Plush foam with rocker design
- Weight: 310g (men's size 10)
- Drop: 8mm
- Terrain: Walking, light activity
- Best for: All-day wear, walking, beginners starting movement
- Durability: Extended casual wear
- Support: Neutral with stability features
- Customer reviews: 4.7/5 - "Most comfortable Nike ever," "Perfect for walking"
- Price: $120
### Beginner-Friendly Options
**Nike Revolution 7** (Product Code: FB2208)
- Category: Entry-level trainer
- Cushioning: Foam cushioning (standard)
- Weight: 283g (men's size 10)
- Drop: 9mm
- Terrain: Road, treadmill, gym
- Best for: Beginning runners, budget-conscious, casual exercise
- Durability: 250-350 miles
- Support: Neutral
- Customer reviews: 4.3/5 - "Great starter shoe," "Affordable quality"
- Price: $70
**Nike Downshifter 13** (Product Code: DM3794)
- Category: Budget-friendly trainer
- Cushioning: Foam cushioning with good support
- Weight: 289g (men's size 10)
- Drop: 10mm
- Terrain: Road, treadmill
- Best for: New runners, gym workouts, budget option
- Durability: 250-350 miles
- Support: Neutral
- Customer reviews: 4.2/5 - "Good value," "Comfortable for beginners"
- Price: $75
## Recommendation Logic
Match user needs to shoes using these criteria:
**Activity Type Matching**:
- Marathon training → Pegasus 41, Vomero 18, Alphafly 3 (if experienced)
- Half marathon → Pegasus 41, Zoom Fly 6, Vomero 18
- 5K/10K → Pegasus 41, Zoom Fly 6, Structure 26 (if stability needed)
- Trail running → Terra Kiger 10, Wildhorse 8
- Casual/fitness → Revolution 7, Downshifter 13, Motiva
- Speed work → Zoom Fly 6, Alphafly 3 (experienced only)
- Recovery runs → Vomero 18, Invincible 3
**Frequency Considerations**:
- 5+ times/week → Durable options (Pegasus 41, Structure 26, Wildhorse 8)
- 2-4 times/week → Versatile trainers (Pegasus 41, Vomero 18)
- 1 time/week or less → Entry-level (Revolution 7, Downshifter 13)
**Terrain Matching**:
- Road only → Any road shoe based on other factors
- Mix road/trail → Pegasus 41 (light trail capable) or suggest 2 shoes
- Primarily trail → Terra Kiger 10 or Wildhorse 8
- Track → Zoom Fly 6, Pegasus 41
**Comfort Priority**:
- Maximum cushioning → Vomero 18, Invincible 3
- Responsive feel → Pegasus 41, Zoom Fly 6
- Lightweight → Terra Kiger 10, Zoom Fly 6, Alphafly 3
- Support/stability → Structure 26
- Durability → Wildhorse 8, Pegasus 41
**Experience Level**:
- Beginner → Revolution 7, Downshifter 13, Invincible 3, Motiva
- Intermediate → Pegasus 41, Vomero 18, Structure 26
- Advanced → Zoom Fly 6, Alphafly 3, Terra Kiger 10
## Output Format
Provide your recommendations in this format:
[Shoe Name] - [Reason]
[Shoe Name] - [Reason]
[Shoe Name] - [Reason]
## Quality Standards
- Always recommend shoes that genuinely match the stated criteria
- Reference specific technical features that address user needs
- Rank by best overall fit, not by price or popularity
- If user needs conflict (e.g., wants maximum cushioning AND lightweight), acknowledge the tradeoff in recommendations
- Never recommend racing shoes to beginners
- For multiple activities, prioritize their primary stated activity
Why compare variations? To learn what actually moves the needle. You'll often find that prompt engineering has more impact than model selection.
Step 3: Select Models to Test
Don't just pick one. Test across:
- - Latest frontier models (GPT-4, Claude Sonnet, Gemini)
- - Smaller, faster models
- - Specialized models for your domain
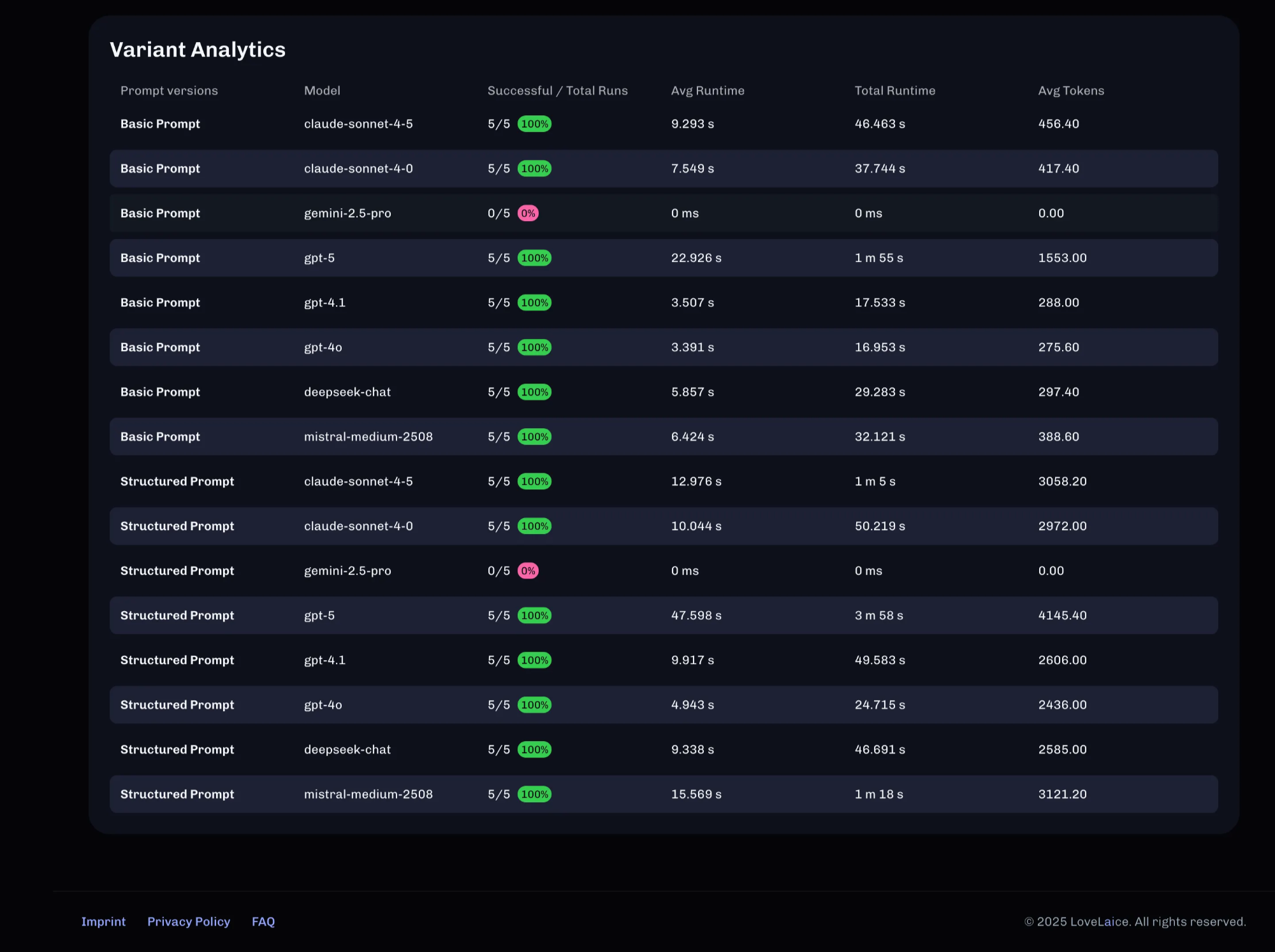
Only through experimentation you can learn if the latest, most expensive model is the best for your use case. Some learnings from our experiments:
- - GPT-4o: Great for deep reasoning, poor for structured tasks
- - Smaller models: Often better (and 100x cheaper) for specific, structured tasks
Step 4: Create Test Cases
If you don't yet know what your input data will look like, how you'll collect it, or what format works best, that's fine. Start with your best guess based on the data you know you can collect from users. Even if this isn't the final format you'll use to send data to the LLMs, you can still determine whether AI can solve your use case—and with what accuracy and cost.
If you already know, you can also add an expected output for each test case. If your use case is more complex and there isn’t one single correct answer, use manual evaluations to assess the AI responses.
Don't just test happy paths. Test:
Happy Paths:
- - Clear, complete information
- - Obvious correct answer
Edge Cases:
- - Conflicting requirements ("fast running + maximum cushion")
- - Missing information
- - Extreme values
- - Category boundaries
Real-World Messiness:
- - Typos and grammar errors
- - Ambiguous requests
- - Unusual combinations
**Example Test Set for Nike - I made my best guess on what the user data could be**
Test Case 1:
Activity type: "Track workouts and tempo runs - training for a fast 10K"
Running frequency: "4 times per week including 2 speed sessions"
Terrain: "Track and roads"
Comfort priority: "Lightweight and responsive - want to feel fast"
Experience level: "Intermediate runner, comfortable with speed work"
Test Case 2:
Activity type: "Want to do everything - roads, trails, gym, and maybe race a 5K"
Running frequency: "3 times per week but inconsistent"
Terrain: "Mix of everything - roads, some trails, treadmill"
Comfort priority: "Want maximum cushioning but also want something lightweight and fast"
Experience level: "Ran in high school but took 10 years off, getting back into it"
Test Case 3:
Activity type: "Training for my first marathon"
Running frequency: "5-6 times per week, including long runs up to 20 miles"
Terrain: "90% road running, some park paths"
Comfort priority: "Need a balance - cushioned enough for long runs but still responsive"
Experience level: "Been running for 3 years, completed several half marathons"
Step 5: Run and Evaluate
The Magic of Side-by-Side Comparison:
When you test multiple models and prompts simultaneously, you get:
- - 2 prompts × 5 test cases × 8 models = 80 responses to evaluate
Critical evaluation insight
Don't show which model produced which result during evaluation. This eliminates bias. You might discover your assumptions about "best models" are wrong.
What to evaluate:
- - Accuracy: Did it identify correct recommendations?
- - Format compliance: Did it follow output structure?
- - Edge case handling: Did it break on unusual inputs?
- - Reasoning quality: Does the explanation make sense?
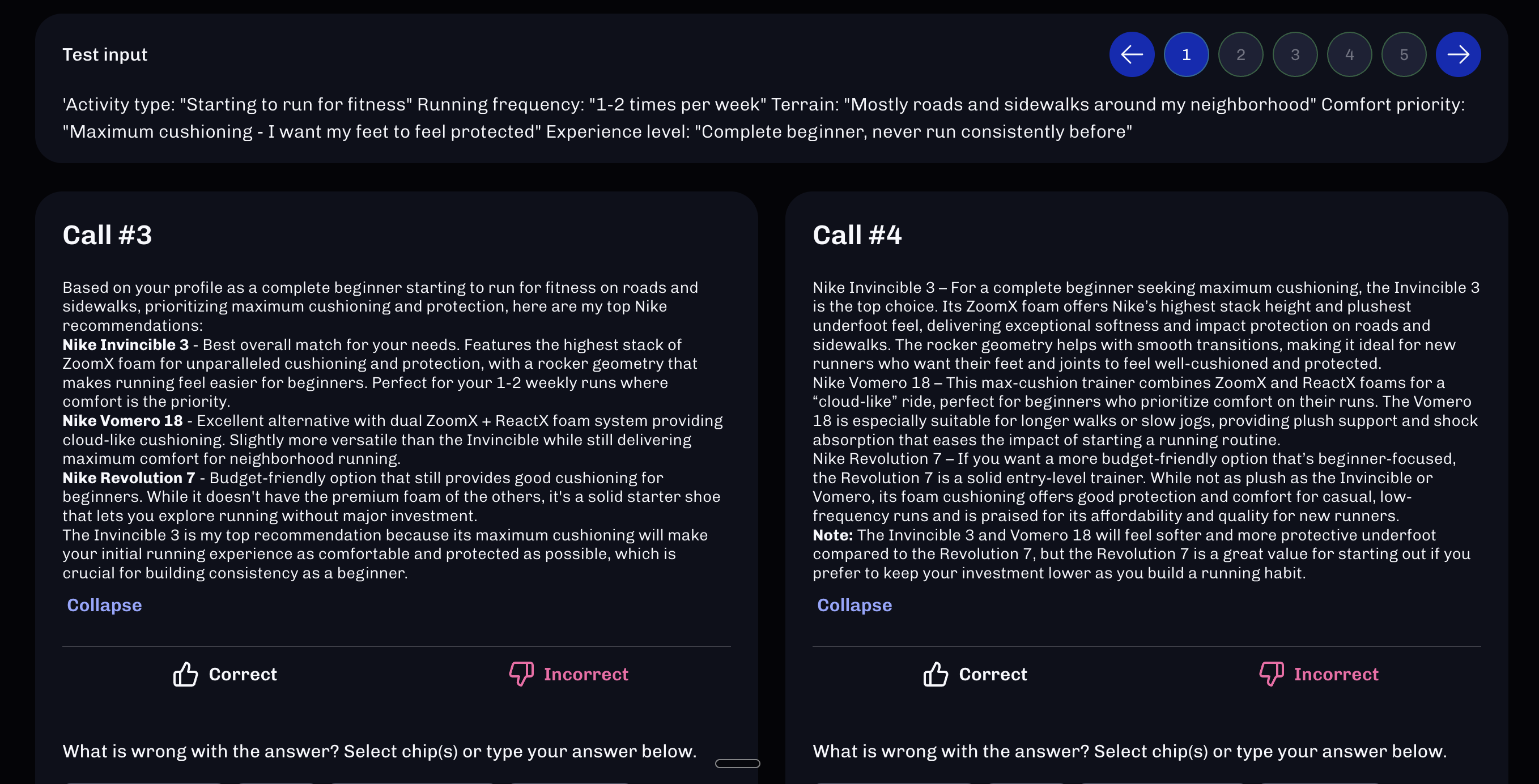
Step 6: Analyze and Iterate
Look for patterns:
- - Were does the AI fail and how could you improve prompt instructions to cover those failures?
- - Which responses handle edge cases better?
- - Where does format compliance break down?
Common issues found:
- - Ignoring instructions: Model improvises instead of following format
- - Potential Fix: More explicit format requirements, add examples
- - Providing the wrong recommendation: Doesn’t follow the recommendation instructions
- - Potential Fix: Provide complete product list in system prompt or add instructions for how to handle cases where it cannot recommend or how to handle edge cases
- - Ignoring context: Gives generic answers/recommendations
- - Potential Fix: Add more domain expertise through your prompt instructions
After a few iterations you will get a better understanding of what is possible, how you can unlock more value, which models best perform for your use case and then you can narrow down your explorations and optimize for cost and speed.
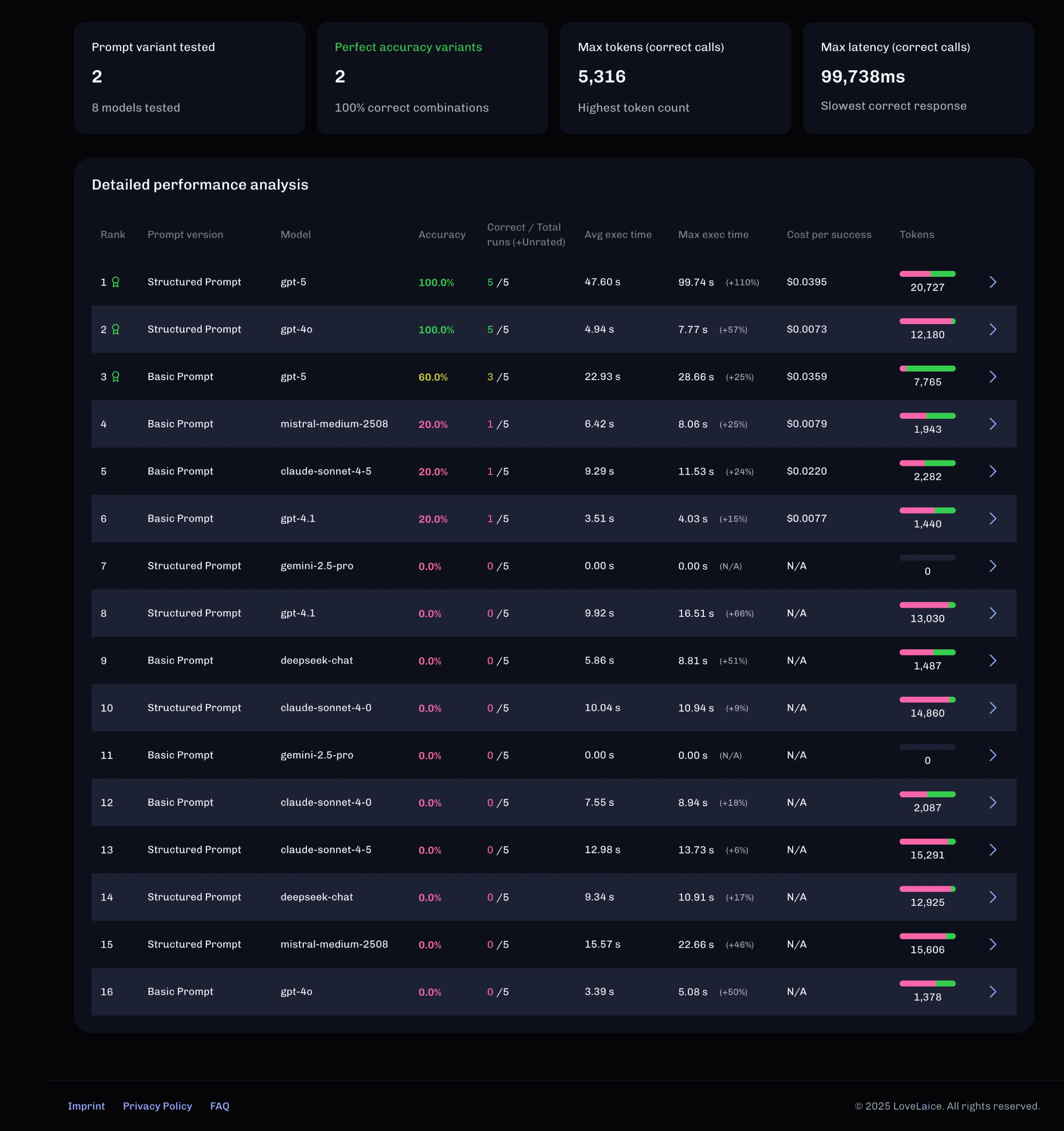
Key Insights:
- - Prompt engineering > Model selection: Structured prompt improved results by 40-80% across all models, except claude-sonnet
- - Cost-quality trade-off: GPT-4 (older, cheaper) with good prompting matched GPT-5 at 80% lower cost
- - Format compliance varies: Some models ignored output format despite explicit instructions
Decision: For production, further testing is required, but few leads have been identified:
- - GPT-4o achieved identical 100% accuracy but with dramatically better performance - 4.9 seconds average latency versus GPT-5's 47.6 seconds.
- - The Structured Prompt was the decisive factor in achieving high accuracy. Every model except GPT-5 failed completely (0% accuracy) with the Basic Prompt, while GPT-5 managed only 60%.
- - Before full deployment, expand testing to 50-100 additional diverse user scenarios to confirm the 100% accuracy holds at scale across different activity combinations and preference conflicts.
Section 5: FAQ from PMs and Product Builders
Q: "Why specify input format if the AI will receive it anyway?"
Answer: Three reasons:
- - Robustness: What if a user doesn't complete the questionnaire? AI needs to know what to expect and how to handle missing data.
- - Consistency: Explicitly stating format helps AI parse and use the data correctly across all cases.
- - Edge case handling: When format is defined, you can specify behavior for empty/invalid inputs.
Test this yourself: Run the same prompt with and without input format specification. In most cases, performance improves when format is specified.
Q: "Couldn't we provide products via URL so AI fetches them directly?"
Answer: Technically yes, but consider:
Problems:
- - Model limitations: Only certain models support web search
- - Cost explosion: Fetching and parsing a webpage adds 100x cost per request
- - Latency: Much slower response times
- - Scale: Nike gets millions of requests – imagine parsing their website millions of times monthly
Better approach: Use RAG (Retrieval Augmented Generation) – a database optimized for LLM queries.
For learning purposes: Start simple (products in prompt) then optimize for scale.
Q: "Why not use fine-tuning for high-volume use cases?"
Answer: Fine-tuning might be worth it, but:
- - Establish a baseline first: You need to know what's achievable with off-the-shelf models before investing in fine-tuning
- - Cost and maintenance: Fine-tuning is expensive and requires ongoing maintenance as models evolve
- - Frontier models improve faster: Consistent evidence shows general frontier models outperform domain-specific fine-tuned models because progress is so rapid
- - Structured prompts often sufficient: Most teams find that well-crafted prompts match or exceed fine-tuned model performance
Test systematically first, then make informed decision.
Q: "What about structured output to force format compliance?"
Answer: Absolutely use it – but in the right phase:
Early exploration phase:
- - Use free-form output
- - Learn how models "think"
- - Identify what works content-wise
- - Easier to evaluate and compare
Production preparation phase:
- - Add structured output constraints
- - Lock down format
- - Optimize for reliability
Why this order? Content quality matters more than format initially. Once you've found the "secret sauce," then optimize format.
Section 6: Common Mistakes
These are the mistakes that cost teams months of wasted effort and thousands in unnecessary costs. We've seen them across every workshop, from early-stage startups to established companies. They're all avoidable. Here's what to watch for:
❌ Choosing Technology First
Problem: "Let's use GPT-4 because it's the best" Better: Test the problem across models, then choose based on data
❌ Testing Only Happy Paths
Problem: Works perfectly in demo, breaks in production Better: Spend 70% of test cases on edge cases and errors
❌ Ignoring Cost at Small Scale
Problem: "It's only €0.05 per request" Better: Calculate at target scale. 1M users = €50k/month
❌ Shipping Without Systematic Testing
Problem: Deploy first, then add evaluations and testing Better: Establish accuracy baseline before deployment
❌ Writing Prompts Like Tutorials Show
Problem: One-sentence prompts don't capture domain expertise Better: Structure prompts with markdown, context, examples, exit strategies - experiment with multiple prompt versions and understand what moves the needle
❌ Assuming Newer = Better
Problem: Always using latest model Better: Understand which model bets performs for your use case by testing and experimenting with your data across multiple models
❌ Not Handling Edge Cases in Prompt
Problem: AI improvises/hallucinates when confused Better: Explicitly specify behavior for edge cases. Improve your prompt at each iteration based on the failure patterns you noticed in the response evaluation.
Section 7: Resources & Tools
For Experimentation:
- - Lovelaice – Multi-model testing, side-by-side evaluation, blind testing, AI-improvement ideas for further iterations
- - OpenAI Playground – Good for single model testing
- - Anthropic Console – Claude-specific testing
For Learning:
- - OpenAI Prompt Engineering Guide
- - Anthropic's Prompt Engineering documentation
- - DeepLearning.ai for more prompt engineering and AI building free courses:
Try It Yourself
Want to run the Nike experiment yourself?
Sign up for Lovelaice and find it in our experiment library
Free trial includes:
- - Access to 6+ models
- - 10 test runs
- - Side-by-side evaluation interface